计算机发展早期,编码只有ASCII编码,但ASCII编码只能够用来表示拉丁字母、数字以及一些特殊符号,而语言不止英语一种,例如中文一个字节是不够表示的,最少需要两个字节,并且需要兼容ASCII编码,不能与之发生冲突。为了解决传统字符编码方案的局限性,所以Unicode编码应运而生。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
在文字处理方面,统一码为每一个字符而非字形定义唯一的代码(即一个整数)。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器。
几乎所有电脑系统都支持基本拉丁字母,并各自支持不同的其他编码方式。Unicode为了和它们相互兼容,其首256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。举例来说,全角格式区段包含了主要的拉丁字母的全角格式,在中文、日文、以及韩文字形当中,这些字符以全角的方式来呈现,而不以常见的半角形式显示,这对竖排文字和等宽排列文字有重要作用。
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。例如:“马”的Unicode是U+9A6C。
Unicode就相当于一张表,建立了字符与编号之间的联系,它是一种规定,Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
除了直接转换为二进制的策略,Unicode 可以使用的编码有三种,分别是:
1 | UFT-8:一种变长的编码方案,使用 1~6 个字节来存储; |
①Unicode其实应该是一个码值表。(百度百科:Unicode的功用是为每一个字符提供一个唯一的代码(即一组数字))。
②UTF-8/UTF-16/UTF-32是通过对Unicode码值进行对应规则转换后,编码保持到内存/文件中。UTF-8/UTF-16/UTF-32都是可变长度的编码方式。(后面将进行Unicode码值转换为UTF-8的说明)。
③我们平常说的 “Unicode编码是2个字节” 这句话,其实是因为windows默认的Unicode编码就是UTF-16,在常用基本字符上2个字节的编码方式已经够用导致的误解,其实是可变长度的。在没有特殊说明的情况下,常说的Unicode编码可以理解为UTF-16编码。
④UTF-32是因为UTF-16编码方式不能表示全部的字符而扩充的编码方式。
ps:显示的字符是表现形式,具体内存中的编码方式和字符显示之间通过中间层进行转换。(根据编码规则,1个字符可能对应内存中1个到几个字节。)
这里转换为二进制后计算机的储存问题:计算机在存储器中排列字节有两种方式:大端法和小端法,大端法就是将高位字节放到底地址处,比如0x1234, 计算机用两个字节存储,一个是高位字节0x12,一个是低位字节0x34
UTF-8编码不存在字节序大小端问题!(因为字节序只影响同时处理多于两个字节的编码方式,比如UTF-16/UTF-32,而UTF-8是按照单字节进行处理的)
UTF-8的解码都必须先读取首字节获取字节数,所以必须找到首字节的第一位要么是0,要么是110/1110/11110/111110/1111110,所以上面的“中”字,无论是保存为11100100 10111000 10101101还是10101101 10111000 11100100,都必须要先找到11100100这个字节,所以UTF-8从机制上就能避免字节序的问题。
UTF-16/UTF-32存在字节序问题(UTF-16常用情况下一次处理2个字节/UTF-32一次处理4个字节)!一个“奎”的Unicode码值是0x594E,“乙”的Unicode码值是0x4E59。如果我们的UTF-16字节数据是0x594E,那么这是“奎”还是“乙”?如果大端序,0x594E是“奎”,如果是小端序,0x4E59,是“乙”。

UTF-8
- UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
1 | 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。 |
- 编码规则:

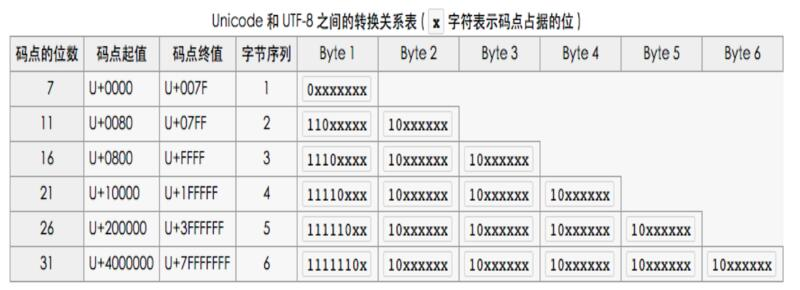

- 对于具体的Unicode编号,进行UTF-8编码的方法:
- 首先找到该Unicode编号所在的编号范围,进而找到对应的二进制格式,然后将该Unicode编号转换为二进制数有(去掉高位的0)最后将该二进制数一次填充入二进制格式的X中,未填充的X变为0.
- 例:马的Unicode编号是:0x9A6C,整数编号是39532,其格式为:1110XXXX 10XXXXXX 10XXXXXX,39532对应的二进制为1001 1010 0110 1100,填入为:11101001 10101001 10101100
UTF-16
- 为了弄清楚UTF-16文件的大小尾序,在UTF-16文件的开首,都会放置一个U+FEFF字符作为Byte Order Mark(UTF-16LE以FF FE代表,UTF-16BE以FE FF代表),以显示这个文字档案是以UTF-16编码,其中U+FEFF字符在UNICODE中代表的意义是ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
- 使用2字节或者4字节进行编码
- 字符按照UTF-16进行编码的规则是: - 字符的值小于0x10000的用等于该值的16位整数来表示。 - 字符的值介于0x10000和0x10FFFF之间的,用一个值介于0xD800和0xDBFF(在所谓的高8位区)的16位整数和值介于0xDC00和0xDFFF(在所谓的低8位区)的16位整数来表示。 - 字符的值大于0x10FFFF不能按照UTF-16进行编码。注意:在0xD800和0xDFFF间的值是特别为UTF-16预留,所以不应该将任何字符的值指定为这个区间内的数值。
1 | D800-DB7F High Surrogates 高位替代 895 |
- 高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。
- 如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。我们将这个范围写成二进制:
1 | 1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111 |
- 按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到
1 | 1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111 |
- 即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代。
UTF-32
- UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,赢得了效率。
- BOM(Byte Order Mark)
1 | ①为了保证编码和解码字节顺序问题(因为只有保证编码和解码的规则一致才能保证是同一个字符),所以Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。 |
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1259742453@qq.com

